Why This Matters
When AI systems encounter complex, multi-step problems in the real world, such as analyzing financial reports or answering questions that require calculation and judgment, they often fail silently or give wrong answers without explanation. ProSEA is a multi-agent framework that solves problems through iterative exploration: when one approach fails, the system learns from the failure and adapts its strategy, much like a human expert would.
The Problem
Existing AI agent frameworks struggle with complex reasoning tasks that require decomposition, calculation, and judgment. Standard approaches like RAG pipelines and ReAct agents either retrieve the wrong information, fail to perform multi-step calculations accurately, or cannot adapt when their initial approach does not work.
A key limitation is that prior multi-agent systems do not propagate structured failure feedback. When an agent fails, the system typically just retries or gives up, rather than learning from the specific reason for failure and adjusting the plan accordingly.
Approach
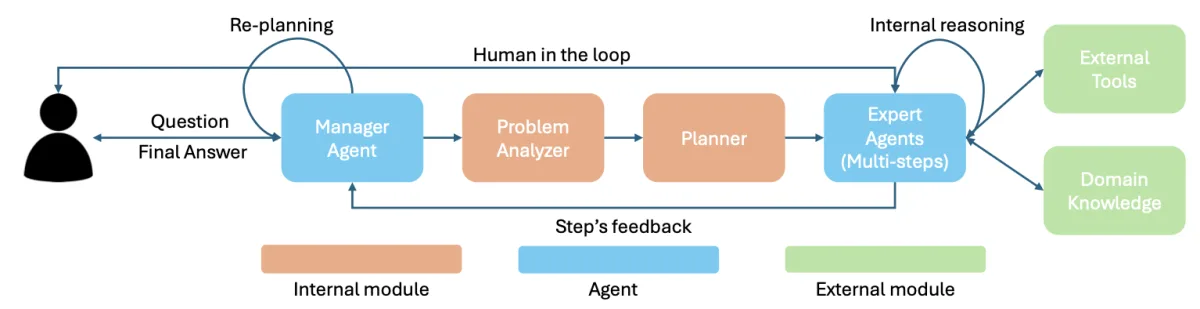
ProSEA introduces a hierarchical multi-agent architecture with four principal components:
- Manager Agent:the central orchestrator that receives queries, coordinates information flow, and makes decisions about when to replan.
- Problem Analyzer:performs preliminary analysis, extracting constraints and assumptions from the problem statement.
- Planner:generates multi-step solution strategies with task decomposition, and can regenerate plans based on feedback.
- Expert Agents:domain-specialized agents that execute individual steps through reasoning, tool usage, and user interaction.
The key innovation is the iterative exploration mechanism: Expert Agents report not only success or failure but also detailed reasons for failure and newly discovered constraints. The Manager Agent processes this structured feedback and triggers adaptive replanning, generating new hypotheses that account for discoveries made during previous iterations. This cycle continues until either a complete solution is found or sufficient exploration has been performed.
The framework operates autonomously while also supporting human collaboration when needed.
Key Results
Evaluated on the FinanceBench benchmark (150 curated financial questions requiring comprehension of 10-Ks, 10-Qs, 8-Ks, and earnings reports):
- ProSEA achieved 93.2% overall accuracy, compared to LlamaIndex RAG (56.7%), LangChain ReAct (81.6%), and OpenAI Assistants (42.7%).
- State-of-the-art on four difficulty categories: 0-RETRIEVE: 98%, 1-COMPARE: 100%, 2-CALC-CHANGE: 100%, 5-EXPLAIN-FACTORS: 100%.
- Comparable to DANA (95.3%) while operating fully autonomously, without requiring the extensive domain engineering that DANA depends on.
- On 3-CALC-COMPLEX, ProSEA scored 95% vs. DANA's 100%.
Impact
ProSEA has been validated in enterprise settings and demonstrates that a general-purpose multi-agent framework with adaptive replanning can achieve performance comparable to domain-engineered systems. The framework's modular design means it can be applied to domains beyond finance. The paper presents a new paradigm for AI problem-solving where structured failure feedback drives exploration rather than mere retries.
Citation
@article{nguyen2025prosea,
title={ProSEA: Problem Solving via Exploration Agents},
author={Nguyen, William and Luong, Vinh and Nguyen, Christopher},
journal={arXiv preprint arXiv:2510.07423},
year={2025}
}