SemiKong: Curating, Training, and Evaluating A Semiconductor Industry-Specific Large Language Model
OSAI4MU-25 Workshop, AAAI, 2025
Why This Matters
Semiconductor manufacturing is one of the most technically demanding industries in the world, yet engineers have had to rely on general-purpose AI tools that lack the specialized knowledge needed for chip design and fabrication. SemiKong is the first open-source large language model built specifically for the semiconductor industry, giving engineers an AI assistant that understands the unique physics, chemistry, and processes of chipmaking.
The Problem
General-purpose LLMs lack the deep domain expertise required for semiconductor manufacturing tasks. The industry involves highly specialized knowledge about processes like etching, lithography, and deposition, with unique terminology and problem-solving patterns that general models struggle with.
There was no publicly available, domain-specific language model tailored to this industry, forcing engineers to either rely on inadequate general tools or proprietary solutions.
Approach
The team curated a large-scale semiconductor-specific corpus totaling 525.6 million tokens, drawn from:
- 129 semiconductor books and chapters
- 708 etching-specific research papers
- 20,000 general semiconductor research papers
- 50,000 instruction pairs (covering semiconductor concepts, complex etching problems with mathematical reasoning, and standard etching process questions)
SemiKong was built by performing continued pre-training on Meta's Llama 3 (both 8B and 70B parameter versions), followed by supervised fine-tuning (SFT) on the curated instruction dataset. Post-training steps included quantization (GPTQ) and LoRA adapter merging.
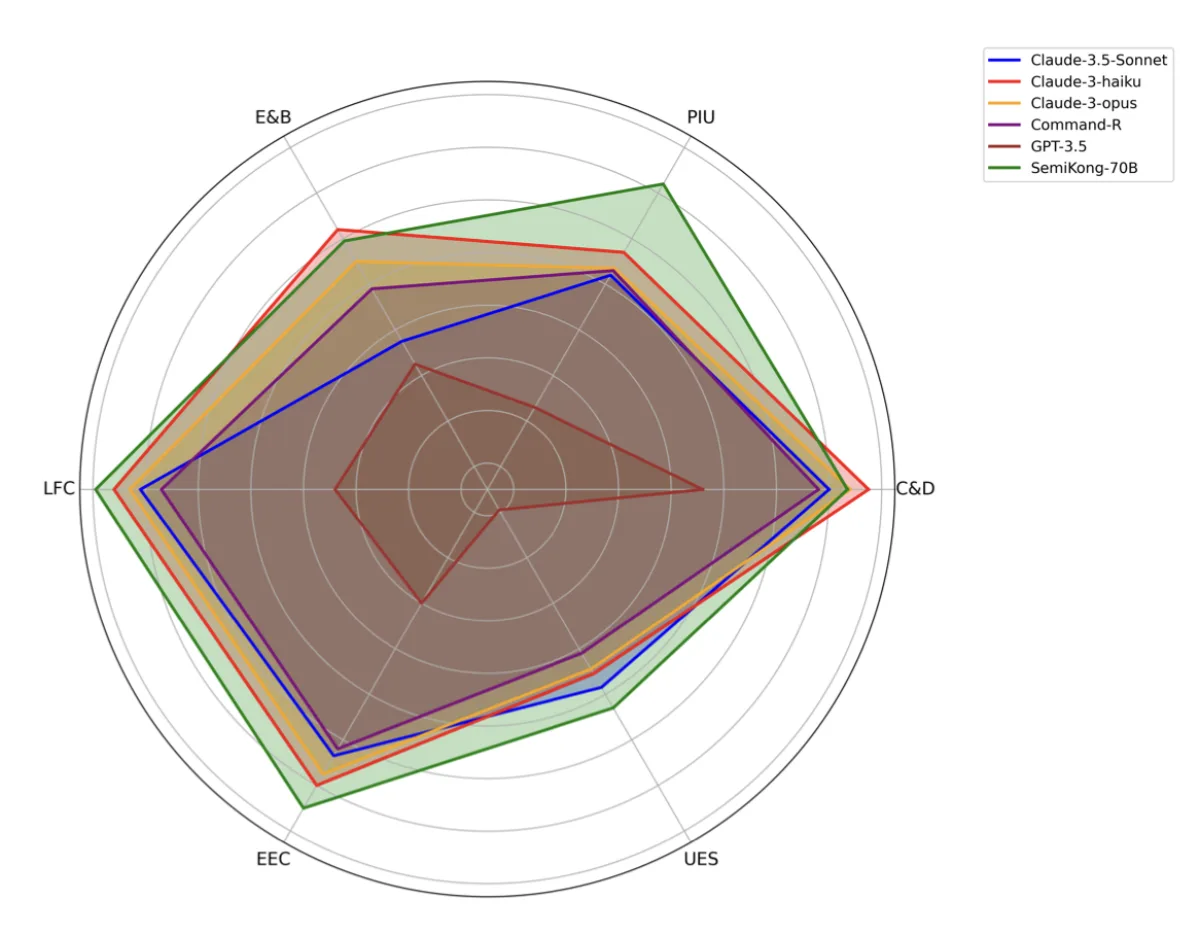
The authors also developed a novel evaluation framework with six domain-specific scoring criteria: Clarity and Directness (C&D), Practicality and Immediate Usability (PIU), Efficiency and Brevity (E&B), Logical Flow and Coherence (LFC), Expert-to-Expert Communication (EEC), and Use of Examples and Specificity (UES). The evaluation dataset consists of 987 questions at easy, medium, and hard difficulty levels.
Key Results
- SemiKong 70B achieved a total score of 24.02, outperforming Llama 3 70B (22.35) across all six evaluation metrics.
- Outperformed all tested commercial models: Claude-3.5-Sonnet (21.25), Claude-3-Haiku (22.16), Claude-3-Opus (21.75), Command-R (21.20), and GPT-3.5 (17.90).
- Domain-specific pre-training matters: SemiKong 8B with both pre-training and SFT (20.81) outperformed the SFT-only version (20.51), which in turn outperformed the base Llama 3 8B (20.49).
- Training resources: SemiKong 8B required approximately 150 hours on 4x NVIDIA A100 80GB GPUs; SemiKong 70B required approximately 200 hours on 8x NVIDIA A100 80GB GPUs.
Enterprise Adoption & Media Coverage
SemiKong has been adopted by Tokyo Electron for root cause analysis, reducing troubleshooting time by 30%. It also received significant media coverage and industry recognition:
- Featured in VentureBeat
- Covered by MSN
- Shared by Yann LeCun
- Featured on Meta AI Blog
- Covered by Tom's Hardware
- Covered by MarkTechPost
- Covered by Digialps
- Covered by Gadgets360
Citation
@article{nguyen2024semikong,
title={SemiKong: Curating, Training, and Evaluating A Semiconductor Industry-Specific Large Language Model},
author={Nguyen, Christopher and Nguyen, William and Suzuki, Atsushi and Oku, Daisuke and Phan, Hong An and Dinh, Sang and Nguyen, Zooey and Ha, Anh Hai and Raghavan, Shruti and Vo, Huy and Nguyen, Thang and Nguyen, Lan and Hirayama, Yoshikuni},
journal={arXiv preprint arXiv:2411.13802},
year={2024}
}